Table of Contents
Duplicate Review
Why Review Duplicates?
Databases are overlapped in the sets of records they contain. When you run similar search strategies against multiple databases for your review, you are likely to identify the same study multiple times. Additionally, a single database itself will often contain duplicates of the same record! Screening duplicate records out of your review could take quite a while!
AutoLit provides automatic de-duplication, meaning that whenever you import multiple searches, an algorithm compares the DOI, PMID, PMCID, and title, and keeps only one version of a study that matches across these fields with a high enough certainty. While this system is derived from peer reviewed methods research & internally validated, it's not perfect! If you want to ensure that all de-duplicated records are in fact duplicates, Duplicate Review enables manual review of all de-duplication decisions.
Navigate to the Duplicate Review Page
To view duplicates, under Literature Search, select “Duplicate Review” ( red box ).
Alternatively, you can access the same page via the main Literature Search page, which provides the total duplicates that were automatically de-duplicated:

Interpretation
Each row in the duplicate queue corresponds to a record imported by a search. There are two duplicate types:
- Duplicate: The record was detected as a duplicate of another record within its imported search
- Match: The record was detected as a match to another record already in the nest
The duplicate queue only offers 1 reason for deduplication, although there may have been multiple criteria qualifying the record as a duplicate.
Downloading the Duplicate Queue
Prior to clearing any records from the duplicate records, you may want to download a spreadsheet of duplicates found. It is important to do this BEFORE making any individual decisions or clearing the queue if you want a full record of all duplicates!
The spreadsheet will only download records that are still in the queue.
To do this, click “Download Queue”

Clearing the Duplicate Queue
As noted above, ONLY clear duplicates that you do not need records of in AutoLit, such as after downloading the Duplicate Queue.
Clicking the “Clear Queue” button will remove all duplicates from this queue permanently and confirm that the records in question were correctly de-duplicated.
This is optional– no clearing of the queue is required in order to move forward in the nest.
Review Duplicate Records
After downloading the spreadsheet of duplicates, you are free to explore the list of all records that were removed from the nest as duplicates of existing records. While the basic information about the record is shown in the table, to review an individual record, click on the row to open the Duplicate Review modal.

Alternatively, you can “Clear Queue” and make a bulk decision for all records in the queue. You can decide to keep all the duplicates as separate records, or drop all duplicates, which automatically removes them from your nest.
Manually Edit De-duplication
Once you have selected a record, you can see and edit the bibliographic information of both the record that was kept in the nest and the record that was removed as a duplicate. Any differences in bibliographic information are presented in red text to highlight potential differences. From this page, you can do several things:
1. Override De-duplication
If the de-duplication was in error (and both records should be added to the nest as separate studies), select “Keep Both Records Separately” to over to insert each one into your nest.
2. Confirm De-duplication
If, upon review, a de-duplication decision that you are reviewing is correct, you can click “Keep only this record,” “cancel,” or click out of the modal to confirm the de-duplication decision.
As noted above, if you select “Keep only this record,” the duplicate will be permanently removed from this queue!
3. Edit the Record
If the bibliographic information for the record that was kept is incorrect, you can edit it from this portal. To edit, click on any field and type in the correct bibliographic information.
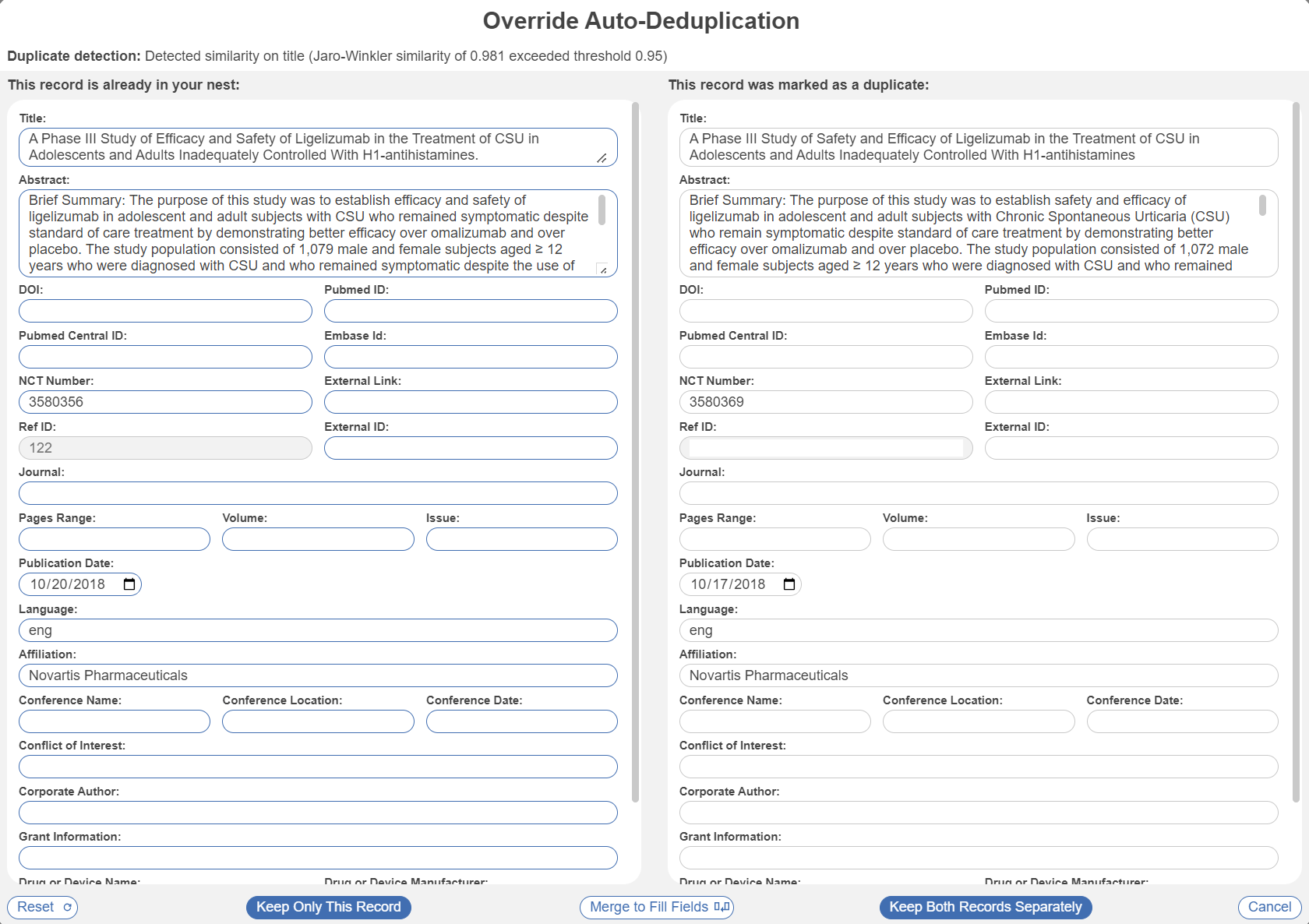
4. Merge to Fill Fields
While you can edit records by typing into each field (see above), you also have the option to auto-fill information from a de-duplicated record into the record you are keeping.
To 'fill fields' from the record on the right to the record on the left (i.e. from the duplicate record to the record that was kept in the nest), select “Merge to Fill Fields” at the bottom of the modal. This will result in:
- Any field that is empty on the left but filled on the right, being copied to the left.
- Any field that is filled on the left being left unchanged.
5. Reset to Original Fields
Made an error and want to revert back to the original inputs? Click Reset.
Implications for PRISMA
Based on the PRISMA 2020 Guidelines, Duplicate records are noted in the “Records Removed before Screening” section:
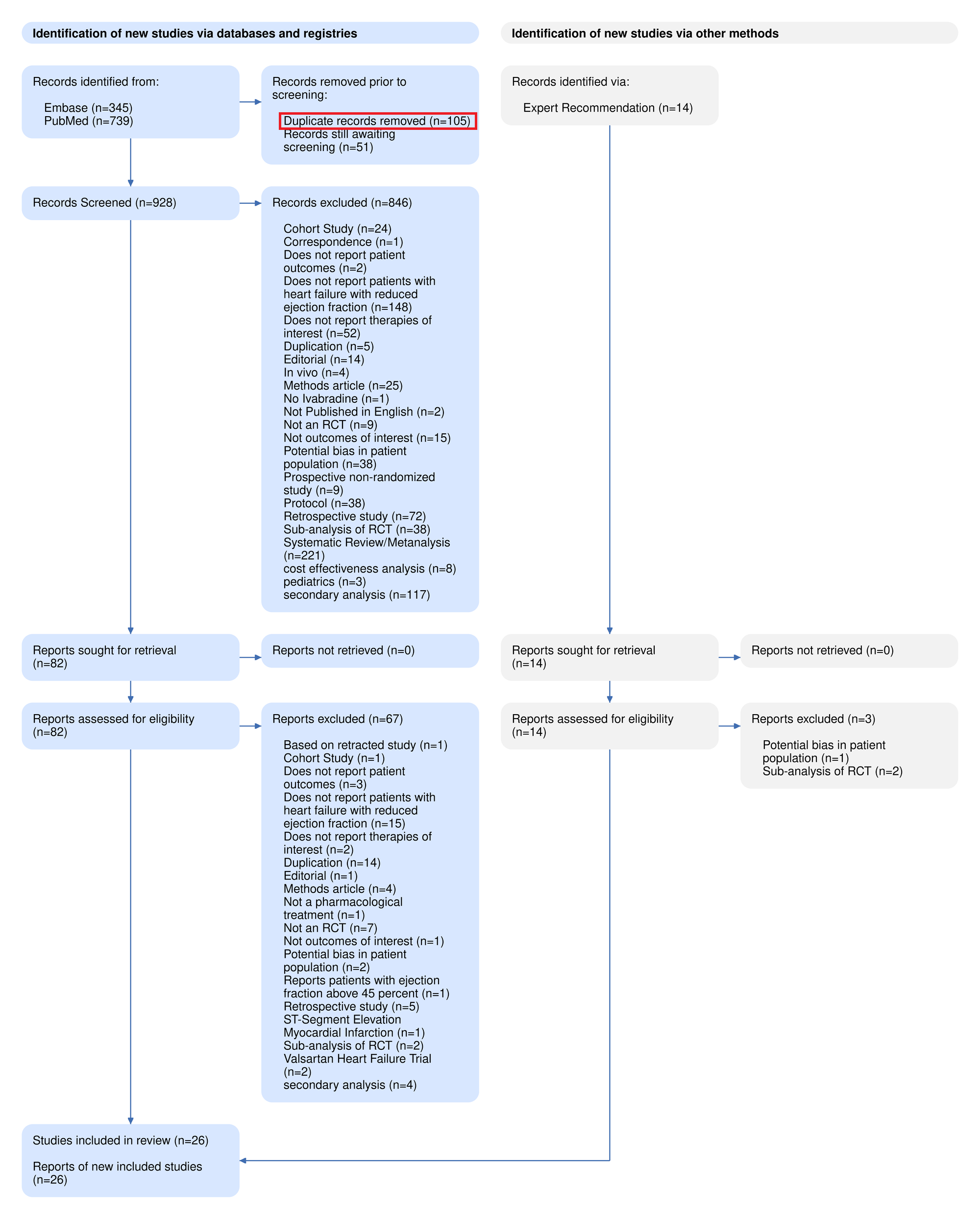
See our PRISMA page for more details on tracking studies through Search and Screening.
Duplicate Counting in Nested Knowledge
There are several key details of how duplicates are counted in Nested Knowledge, which is meant to enable tracking of all duplicate records in AutoLit while still following the PRISMA 2020 guidelines with respect to duplicate counts.
What do the duplicate counts on PRISMA represent?
The duplicate counts on your automatically-generated PRISMA Flow Diagram represent duplicates between databases ('between-database duplicates'). This means that, if you have run multiple searches on a single database and duplicates were found within these searches on the database of interest, they will not be counted on PRISMA.
If you have run searches on multiple databases, regardless of how many searches per database, the duplicate counts will show the number of records that were found on multiple databases.
What do the duplicate counts in the Duplicate Review and Intersections plots represent?
To help understand and manage duplicates between searches from a single database ('between-search duplicates') alongside between-database duplicates, the Duplicate Review and Intersections will provide full counts of all duplicates at the search level (i.e., all duplicates between individual searches regardless of origin). These deduplications can be reviewed, overridden, merged, or kept; see above for full details.
Note that, if Duplicates are cleared from the Duplicate Review, the counts in the Duplicate Review will reflect only Duplicates that have not yet been cleared! However, rest assured, clearing records from the Duplicate Queue has no impact on exports or PRISMA flow diagrams.
Where can I get a record of all 'between-search' duplicates?
If you need an audit record showing all 'between-search duplicates', we offer this as an Export.
To access this, go to Export, and select “CER Builder”. Under this function, select “Screening”, and export either a Word document or Excel sheet of your duplicate numbers.